Computational Photography
Computational Photographyとは
従来のカメラは人間の視覚を模倣し,人間が見ているものと同じような画像を撮影するが,コンピュータビジョンの様々なタスクで使用する際にはカメラは必ずしも人間と同じように撮影する必要はない.むしろ人間を模倣することで必要な情報を捨てているともいえる. コンピュテーショナルフォトグラフィでは,撮影後に画像処理を行うことを前提にその画像処理に特化した画像を撮影することで,従来のカメラ+後処理では不可能な機能の実現や達成しえない高精度な計測を可能とする.
圧縮ビデオセンシング
光線には空間情報や時間情報など様々な情報が含まれるが,通常のイメージセンサは画素が2次元に配置されており,情報をすべて取得することは困難である.圧縮ビデオセンシングは,画素ごとに露光タイミングをずらした画像を撮影し,再構成を行うことでセンサの時空間解像度を超えた動画を得ることができる.圧縮する際には復元に必要な情報を残す必要があるが,それは復元しないとわからない.よって,圧縮と再構成を同時に最適化することで効率の良い圧縮と高品質な再構成を達成できる.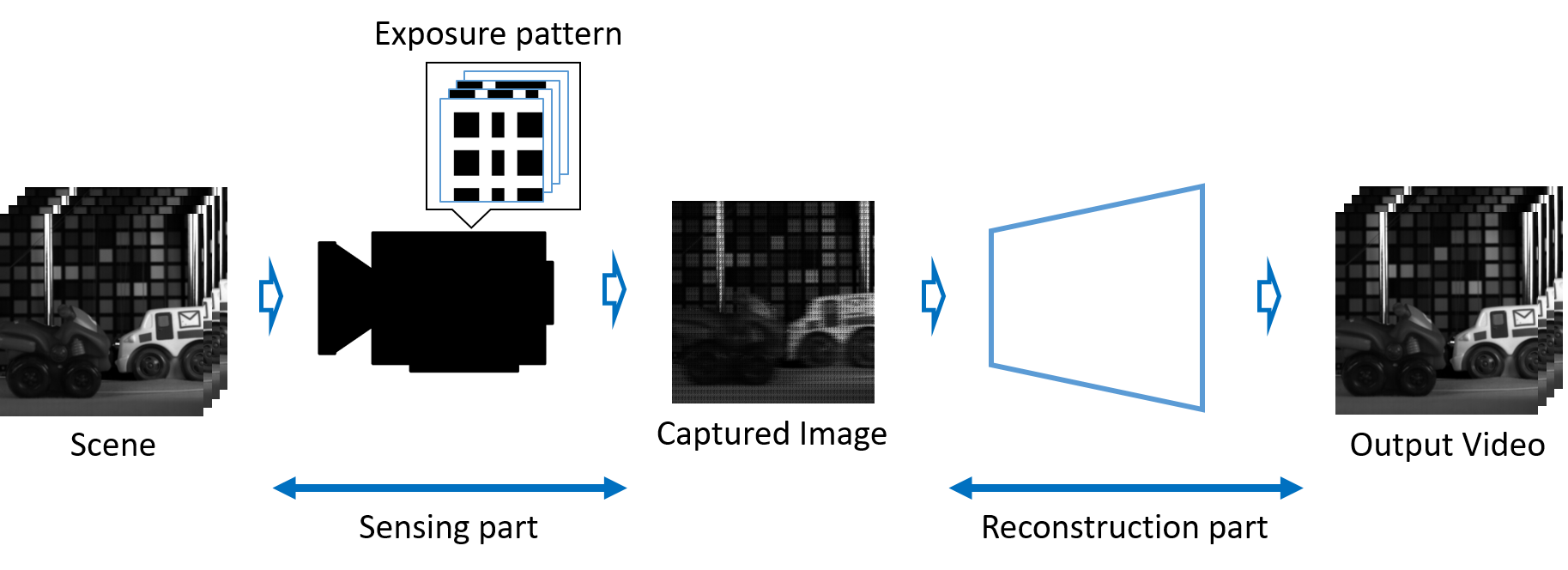 図1:圧縮ビデオセンシングにより,1枚の撮影画像から動画の復元が可能となる
図1:圧縮ビデオセンシングにより,1枚の撮影画像から動画の復元が可能となる
- Michitaka Yoshida, Toshiki Sonoda, Hajime Nagahara, Kenta Endo, Yukinobu Sugiyama, Rin-ichiro Taniguchi, “High-Speed Imaging Using CMOS Image Sensor With Quasi Pixel-Wise Exposure”, IEEE Transactions on Computational Imaging, Vol.6, pp.463-476, 2019
- Michitaka Yoshida, Akihiko Torii, Masatoshi Okutomi, Kenta Endo, Yukinobu Sugiyama, Rin-ichiro Taniguchi, Hajime Nagahara, “Joint optimization for compressive color video sensing and reconstruction under hardware constraints”, Proceedings of the International Conference on Computational Photography (ICCP2020), Saint Louis, U.S.A, 2020.04
- Yoshida Michitaka, Torii Akihiko, Okutomi Masatoshi, Endo Kenta, Sugiyama Yukinobu, Taniguchi Rin-ichiro, Nagahara Hajime, “Joint optimization for compressive video sensing and reconstruction under hardware constraints”, Proceedings of the European Conference on Computer Vision (ECCV2018), Munich, Germany, pp.634-649, 2018.09
符号化露光画像を用いた人物の行動認識
現在,社会では監視カメラやカメラを備えたスマートフォンなどの様々なカメラが普及しており,こうしたカメラで異常な動作を検出したり,IoTデバイスを用いたマンマシンインターフェースなど,人間の行動を分析する需要が高まっている.カメラには,センサの読み出しの制限やカメラと処理サーバのネットワーク帯域の制限のため,空間解像度とフレームレートにはトレードオフがあり高解像度かつ高フレームレートでの撮影やデータ送信は困難である.低解像度の動画はオブジェクトの詳細が失われ,低フレームレートの動画はモーションの詳細が失われるため,低解像度や低フレームレートの動画は行動認識には適していない.この問題を解決するひとつのアプローチとして,符号化画像から動画を復元する,圧縮ビデオセンシングによる手法が考えられる.圧縮ビデオセンシングでは,ランダムなタイミングで露光可能なセンサを用いて撮影された単一の符号化露光画像から,センサの読み出しよりも高いフレームレートの動画を再構成することが可能である.符号化露光画像は動画が再構成できるというように時間情報を有しているので,単一の符号化露光画像から行動を認識できるのではないかと考えた.本研究では,行動認識のための符号化露光画像を利用を提案する.Deep Learningを使用して,分類モデルと同時に符号化露光パターンを最適化する.提案手法は,単一の符号化露光画像のみから人間の行動認識できることを実証した.同一データ量に圧縮する他の手法と比較し,提案手法の利点を示した.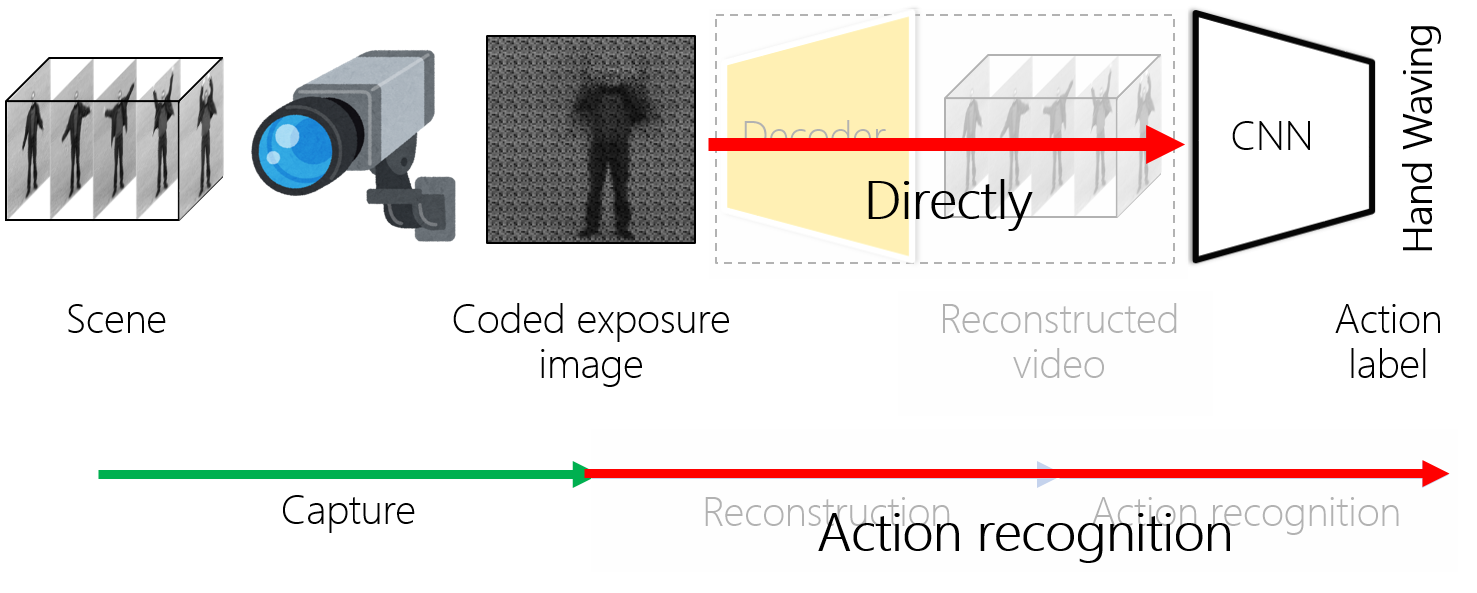 図2:符号化露光画像から動画の復元を行わず直接行動認識を行うことにより,動画と同程度の認識率を維持しながら入力画像のデータ量を大幅に削減できる
図2:符号化露光画像から動画の復元を行わず直接行動認識を行うことにより,動画と同程度の認識率を維持しながら入力画像のデータ量を大幅に削減できる
- Tadashi Okawara, Michitaka Yoshida, Hajime Nagahara, Yasushi Yagi, “Action Recognition from a Single Coded Image”, Proceedings of the International Conference on Computational Photography (ICCP2020), Saint Louis, U.S.A, 2020.04
- 大河原 忠,吉田 道隆, 長原 一, 八木 康史, “符号化露光画像を用いた人物の行動認識”, 情報処理学会コンピュータビジョンとイメージメディア研究会(2019-CVIM-220), 奈良, 2020年1月